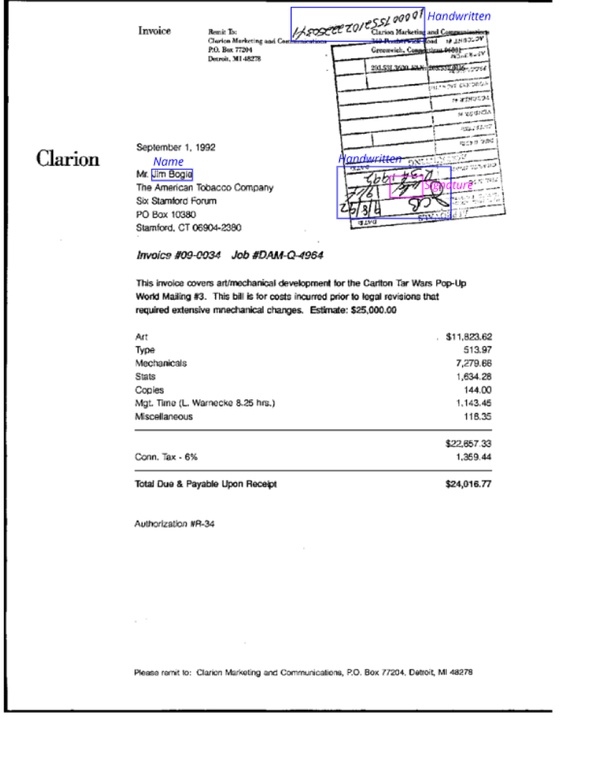
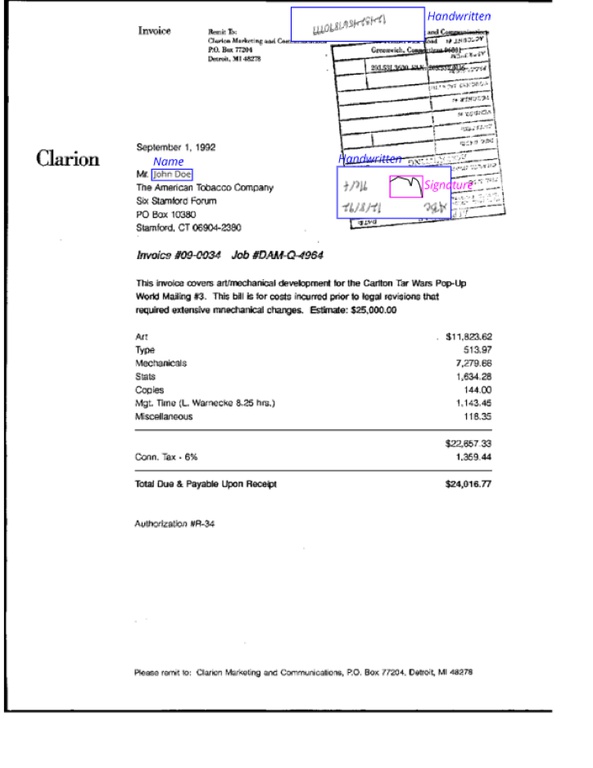
This challenge will award up to $60,000 in total prizes for solutions that can identify personally identifying information (PII) within semi-structured data and then anonymize it.
Why This Matters
Access to data is a major differentiator for businesses in today's global marketplace and can be instrumental in breaking down data silos, extracting business intelligence through machine learning and using AI-driven insights to deliver better experiences. However, a critical consideration to moving forward with these opportunities is assuring data privacy.
Semi-structured text documents are an essential part of many business processes, for example invoices, sales orders, or payment advises. Translating these semi-structured data into structured data is essential to allow further downstream processing and automation.
To foster research and development of machine learning approaches for document processing, it is necessary to allow researchers to work with large amounts of realistic documents. To comply with data protection regulation, companies have to anonymize documents and remove any personally identifying information. This redaction should be done in a way that produces realistic-looking documents and minimizes negative impact on machine learning model training.
Openness is a key principle for SAP as it is the foundation for co-innovation and integration. We are embracing open standards and open source, and are providing rapid access to data and business processes through open APIs, so customers and partners can turn data into value as easy as possible. In return, it is crucial for SAP to use the power and speed of communities to innovate even faster. In this spirit, the winning solutions from the challenge will be open-sourced. Openness creates more value for everybody.
Your Challenge
In this challenge, you will work with a set of 25000 invoices from the public RVL-CDIP DatasetRVL-CDIP Dataset [1,2]. Some of the invoices are (low quality) scans or contain handwritten notes. You are also welcome to use other datasets that are available to you to train your model and maximize its generalizability.
Your tasks are as follows:
Build a model that can identify the bounding boxes of the following types of personally identifying information:
Personal names,
Signatures, and handwritten notes.
Develop a system to redact the content of the bounding boxes with a realistic replacement such that the anonymized data remains effective training data for machine learning tasks. This will require efforts to preserve the style, orientation, imperfections and complexities of the original data. Anonymized substitute text that is simpler and clearer to read than the original data will result in a less comprehensive and less effective training data set.
As ground truth for your models training you will be provided with a sample of bounding boxes of the personally identifying information as specified above.
Guidelines
Prizes
SAP’s Data Anonymization Challenge will award up to $60,000 in total prizes.
Grand Prize Winner: $30,000
2nd Place Winner: $15,000
3rd Place Winner: $5,000
Bonus for Best Task 1 Score: $5,000
Invitation to Final Scoring: $5,000 split evenly between those invited to submit their executable code for final scoring, which will include evaluation on both Task 1 and Task 2 with new data that has not been previously shared with competitors.
In addition to the monetary prizes offered, the winner will be invited to a special event by SAP.
Winning Criteria
A successful solution will accomplish the following:
Task 1: Build a model that can identify the bounding boxes of personally identifying information. Given an invoice as an image, the model should predict a list of the following:
Straight bounding box, (i.e., x1, y1, x2, y2)
a. Category of information: personal name, personal address, phone number, signature, or handwritten note (see personally identifying information specification below).
Task 2: Develop a system to replace the content in the bounding boxes, as given in task 1, with realistic dummy content such that:
Personally identifying information is removed, and
The anonymized data remains effective training data for machine learning tasks. This will require efforts to preserve the style, orientation, imperfections and complexities of the original data. Anonymized substitute text that is simpler and clearer to read than the original data will result in a less comprehensive and less effective training data set.
Personally Identifying Information is defined as:
Personal names
Signatures, and handwritten notes.
Challenge Schedule
Pre-Registration Launches: 9/29/2019
Competitors can join the challenge community.
Challenge Details Released: 9/5/2019
Competitors can now access the complete challenge guidelines and resources, including the scripts to download data, Task 1 scoring scripts, ground truth labels, and example submissions.
Task 1 Leaderboard Opens: 9/30/2019
Competitors can now submit to the Task 1 Leaderboard to track their progress against competitors. The subset of the data used for leaderboard testing will be announced.
Each leaderboard submission must contain a correctly formatted JSON file with the output for only the subset of the data used in leaderboard testing. (See Task 1 File format below.)
Submitted JSON files will be compared against the ground truth labels and scored according to the rules in Task 1 Scoring below.
Competitors can submit to the leaderboard daily and results will be updated daily.
Task 2 Leaderboard Submission Deadline: 11/19/2019 at 5:00 pm Pacific Time
In order to receive preliminary feedback on their Task 2 performance, competitors will be able to submit one redacted invoice to the Task 2 Leaderboard. This feedback will give competitors the opportunity to measure and improve their Task 2 performance before Final Scoring in December. The PNG files for this leaderboard can be found here.
The Challenge Sponsor will grade each redacted invoice to give competitors an indication of their progress.
Task 1 Leaderboard Closes and Finalists Invited to Final Scoring: 12/12/2019 at 5:00 pm Pacific Time
Top scoring competitors from the Task 1 leaderboard will be invited to submit to the Final Scoring as finalists.
The finalists will have one week to prepare their final submission.
Finalists’ Deadline for Submitting to Final Scoring: 12/19/2019 at 5:00 pm Pacific Time
Final submissions due for all finalists invited to the Final Scoring. See the Submission Requirements section below.
Evaluation Period: 12/20/2019 to early 2020
SAP will score finalist submissions as per the Scoring Metrics below
Finalists must be available to debug and troubleshoot their code during this period to ensure SAP can successfully execute it in the specified Test Environment. Failure to do so will result in disqualification.
Winner’s Announced: Early 2020
Winners will be announced and invited to a special event by SAP.
Task Examples
Example of Bounding Box for Task 1:
Example of Redacted Invoice for Task 2:
Please note the colored boxes and labels are for illustrative purposes only and should not be included in your submission.
Submission Requirements
Solution Requirements:
For the first task, you should provide a program which takes a list of PNG-files as an input and outputs a list of labels in the format specified below. Please download the sample implementation in the download section below.
For the second task, you will provide a program that takes a list of JSONs as specified below as an input and writes out a list of anonymized PNG images.
You can use any language or library but you should provide us with a docker image in which your code runs in the Test Environment specified below.
our program should run for inference for 1000 samples in less than an hour; training should run in less than a day for each task in the environment specified below.
Task 1 Leaderboard Submission:
JSON file formatted as per the Task 1 file format.
Task 2 Leaderboard Submission:
One PNG file with all personally identifying information redacted and replaced with anonymized text. The image to be redacted will be released one week prior to the submission deadline
Final Submission for Finalists Invited to Final Scoring: (updated on Dec 11, 2019)
One zip file containing the following for Task 1 & Task 2:
Code that is executable by SAP on the environment specified in Test Environment
README file with clear and concise instructions for running the code. Also, please provide an expected time for training and expected time for inference
For any machine learning model you are using, you should provide us with the trained model as well as instructions on how to retrain the model.
Source code and documentation
Description of your algorithm and approach. Please include any citations to existing research and list any additional datasets you have used and provide links to the datasets (1 - 5 page PDF document)
Task 1 File Format:
The labels for the bounding box should be written in a file consisting of one JSON document per line. The JSON document should have the following schema. It is a JSON object with the keys id,bounding_boxes and bad_quality. The value of id is a string to identify the PNG image of the invoice. The value of bounding_boxes is an array of JSON objects each denoting a bounding box. Each bounding box object has the keys x0, y0, x1, y1, and label. The values of x0, y0, x1, y1 are floating point in the unit interval denoting the coordinates of the bounding box as a ratio. The value of label should be in "name", "handwritten". It denotes the type of content of the bounding box. The value of bad_quality should be a boolean. It indicates that the invoice could not be processed due to bad quality.
Example:
{
"id": "imagesl_lgq30c00_ti01410925.png",
"bad_quality": false,
"bounding_boxes": [{
"x0": 0.253315649867374,
"y0": 0.8,
"x1": 0.2692307692307692,
"y1": 0.882,
"label": "name"
}, {
"x0": 0.3169761273209549,
"y0": 0.64,
"x1": 0.4151193633952255,
"y1": 0.743,
"label": "handwritten"
}, {
"x0": 0.3660477453580902,
"y0": 0.759,
"x1": 0.38726790450928383,
"y1": 0.855,
"label": "handwritten"
}, {
"x0": 0.5570291777188329,
"y0": 0.606,
"x1": 0.6724137931034483,
"y1": 0.664,
"label": "handwritten"
}]
}
Test Environment:
Your code will be tested in the following environment:
Please ensure your solution works without modification in the test environment.
Scoring
Task 1 and Task 2 will be scored separately. All teams will be scored on the first task, but only the top scorers of the first task will be invited to Final Scoring and receive scoring for the second task.
Task 1: Scoring for Task 1 will be based on the number of predicted bounding boxes that match the ground truth in both labels and box placement. We say that the placement of a bounding box B1 is matching another bounding box B2 if its intersection over union is greater than 0.8. In detail, let a(B) be the area of the bounding box B and let B1 ⋂ B2, B1 ⋃ B2 be, respectively, the intersection and union of B1 and B2. Then B1matches B2 if a(B1 ⋂ B2)/ a(B1 ⋃ B2) > 0.8.
For an invoice, a predicted bounding box is matching a ground truth bounding box if both the label is matching and the bounding boxes are matching.
Let m be the number of matching bounding boxes. Further, let ngt be the number of ground truth bounding boxes, and let npred be the number of predicted bounding boxes. The score for a document and category of PII is defined as score = m/ngt *0.75^(npred-m) for ngt > 0 and score = 0.75 ^(npred-m) if ngt = 0. So the score is the ratio of correctly identified boxes penalized by 25% for each additionally predicted box that does not appear in the ground truth data.
The score for the whole document is the average of the scores for each category of PII.
Documents flagged as bad quality will receive a score of 0.35 regardless of the bounding boxes.
We provided a sample implementation of the above scorer in the download section.
Task 2: The second task will be scored by assessing the realism of the anonymized invoices. We will use your submission of anonymized invoices from the provided dataset and other sources. We will manually check if anonymized invoices can be distinguished from real invoices.
Your submission to the second task has to be designed in such a way that the content of the new bounding box does not contain any personally identifying information from the original document. Please make sure to include an explanation in your model description.
Data
For this challenge, you will work with a set of 25000 invoices and invoice-like documents from the RVL-CDIP Dataset [1,2]. Some of the invoices are (low quality) scans or contain handwritten notes.
Dataset: 25,000 invoices and invoice like documents from the RVL-CDIP Dataset [1,2] (download size 37 GB). In the download section you will find a script for downloading and converting the files into the challenge format.
Ground Truth Labels: 1,000 labeled invoices from the dataset
Additionally, we have labeled invoices never previously seen by competitors that will be used as the test dataset for the leaderboard and final scoring.
Download
ZIP-File containing the download-script, labels for task 1, an implementation of the scorer for task 1, and dummy implementations of task 1 and 2 - Access Here.
Downloading of Data Set
Downloading the dataset could take a few hours. Run the following command. It requires convert fromimage-magick.
./download.sh
This script should generate a directory invoices/ containing 25000 png-files.
Training data
The file labels.jsonl contains labels for 1000 invoices. The field id matches the filename in invoices/.
Task 1 Sample
task1_sample.py is a dummy solution for task 1. It creates correctly formatted, random labels. For instance, the following command will create random labels for the invoices in labels.jsonl.
A sample implementation of the scoring algorithms is contained in task1_score.py and metrics.py. The following command will score the random labels created against the reference labels.
./task1_score.py labels.jsonl labels_sample.jsonl
Task 2 Sample
task2_sample.py is a dummy solution for task 2. It redacts sensitive information by drawing a solid box over it.
It can be run as follows.
./task2_sample.py labels.jsonl out
This command will save the redacted images in the directory out/.
This script also has an option to outline the bounding boxes for inspection. This option triggered by adding the --box outline parameter, i.e., ./task2_sample.py --box outline labels.jsonl out2.
Rules
Participation Eligibility:
To be eligible to compete, you must comply with all the terms of the challenge as defined in the Challenge-Specific Agreement.
Submissions must be made in English. All challenge-related communication will be in English.
No specific qualifications or expertise in the field of data anonymization is required.
Registration and Submissions:
Submissions must be made online (only), via upload to the HeroX.com website, on or before the submission deadline. No late submissions will be accepted.
Intellectual Property Rights:
If Challenge Sponsor notifies Innovator that Submission is eligible for a Prize, Innovator will be considered qualified as a finalist (“Finalist”). Challenge Sponsor will require all content and assets developed by Finalists as part of their Submissions to be licensed under the Creative Commons CC BY (4.0) license. Challenge Sponsor will also require all code developed by Finalists as part of their Submissions to be licensed under the Apache License 2.0. Once all development has been completed, all designs, code, content, and assets developed by all Finalists will be released under the Creative Commons CC BY (4.0) and Apache License 2.0.
Selection of Winners:
Prizes will be awarded based on the Winning Criteria section above. In the case of a tie, the winner(s) will be selected based on the highest votes from the Judges.
In the case of no winner, SAP reserves the right to withhold the Prize amount. In place of the original prize amount, SAP will issue a Consolation Prize to the team or individual closest to the winning solution in the amount of at least $5,000 USD and Consolation Prize in the amount of $2,000 USD to the second closest team or individual.
Additional Information
All ineligible applicants will be automatically removed from the competition with no recourse or reimbursement.
No purchase or payment of any kind is necessary to enter or win the competition.
Void wherever restricted or prohibited by law.
References
[1] https://www.cs.cmu.edu/~aharley/rvl-cdip/ A. W. Harley, A. Ufkes, K. G. Derpanis, "Evaluation of Deep Convolutional Nets for Document Image Classification and Retrieval," in ICDAR, 2015
[2] The Legacy Tobacco Document Library (LTDL), University of California, San Francisco, 2007. http://legacy.library.ucsf.edu/.
Please ensure you submit your entries to the Task 1 Leaderboard by Thursday December 12 at 5 pm Pacific Time (Los Angeles). This is your last opportunity to do so! Here's what you need to know:
You do not need to have submitted previously to submit now.
You are able to submit once per day prior to 12 noon Pacific Time and have your submission scored. We strongly recommend submitting early to ensure your submission is in the correct format for scoring
Review the Challenge Guidelines in full to ensure you are clear on all requirements.
Following Thursday's submission deadline, top teams will be invited to the Final Scoring. If you are invited to the final scoring, you will have one week to submit your files. We have updated the files required to make the submission easier for finalists. Here's what you will need to submit:
One zip file containing the following for Task 1 & Task 2:
Code that is executable by SAP on the environment specified in Test Environment of the Challenge Guidelines.
README file with clear and concise instructions for running the code. Also, please provide an expected time for training and expected time for inference
For any machine learning model you are using, you should provide us with the trained model as well as instructions on how to retrain the model.
Source code and documentation
Description of your algorithm and approach. Please include any citations to existing research and list any additional datasets you have used and provide links to the datasets (1 - 5 page PDF document)
The deadline to submit your Task 1 Leaderboard Submission is December 12th at 5 pm PT (Los Angeles time).
You must submit by this deadline in order to be invited to the final scoring. You do not need to have submitted to the Task 2 Leaderboard to submit to this deadline.
Tips:
Ensure you submit to the Task 1 Leaderboard early if you have not already. This will ensure that you have submitted in a format that allows us to score your entry. If you receive a -1 on the leaderboard, your submission was not scored. Please reach out to us if this is the case for you.
The leaderboard is scored everyday at 12 noon Pacific Time (Lost Angeles). You can submit once per day to be rescored. Please wait until your entry has been scored before bringing it back into editing mode and submitting it again.
Review the Challenge Guidelines in full to ensure you are clear on all requirements.
Task 1 Leaderboard Closes and Finalists Invited to Final Scoring: 12/12/2019 at 5:00 pm Pacific Time
Top scoring competitors from the Task 1 leaderboard will be invited to submit to the Final Scoring as finalists.
The finalists will have one week to prepare their final submission.
**Finalists’ Deadline for Submitting to Final Scoring: 12/19/2019 at 5:00 pm Pacific Time
Final submissions due for all finalists invited to the Final Scoring.
**Please ensure you have some time available between 12/12 and 12/19 to submit to final scoring. The details for this are in the challenge guidelines.
Evaluation Period: 12/20/2019 to early 2020
SAP will score finalist submissions as per the Scoring Metrics below
Finalists must be available to debug and troubleshoot their code during this period to ensure SAP can successfully execute it in the specified Test Environment. Failure to do so will result in disqualification.