Over the past 35 years, post-translational protein O-GlcNAcylation has increasingly seduced various biomedical research fields as a bridge to explain environmental influences on signaling and the onset of various diseases. While the O-GlcNAc field recently reached the milestone of 2000 articles, it still lacked a comprehensive inventory, limiting its accessibility to clinical and translational research. We created a participative database (www.oglcnac.mcw.edu) cataloging all O-GlcNAcylated proteins described to date. This user-friendly database tremendously increased the interaction between the O-GlcNAc community and other research fields such as neurodegeneration or cancer biology, writing a new chapter in PTM research.
I (Stephanie Olivier-Van Stichelen, Ph.D.) am a basic scientist trained in O-GlcNAc labs, including Drs. Lefebvre (France) and Hanover (Bethesda, MD). In 2019, I established my research team at the Medical College of Wisconsin (MCW), Milwaukee, WI, thanks to a K99/R00 award. Two months later, Eugenia Wulff-Fuentes joined my lab as my first graduate student, followed closely by Rex Berendt, a research technologist. One year later, Laura Danner became the second graduate student to join our team. We have curated over 2,400 articles leading to the extraction of more than 16,000 proteins and almost 14,000 sites. Shortly after, Florian Malard, Ph.D., joined our team and took this to the next level by creating a semi-automated database platform. Two publications resulted from this collaborative effort: Wulff-Fuentes E, et al. Sci Data 2021(PMID: 33479245) and Malard F et al., Database 2021 (PMID: 34279596). As of early 2022, the initial publication received enough citations to place it in the top 1% of the academic field of Biology & Biochemistry based on a highly cited threshold for the field and publication year (Essential Science indicators) and is the most cited O-GlcNAc publication for the last 2 years (Web of Science).
In March 2020, we received the email from our institution telling us what we had suspected for days: we were sent home amid the COVID19 pandemic! At that point, the lab had only been open for 1 year, most of it acclimatizing to teaching, recruiting students, and equipping the lab with all the biochemistry tools we need for our research. We did not have enough data yet to start writing papers but to keep working together, we decided to write a review! Because most topics were already covered, we started the first meta-analysis of the human O-GlcNAcome, e.g., all the proteins modified by O-GlcNAcylation.
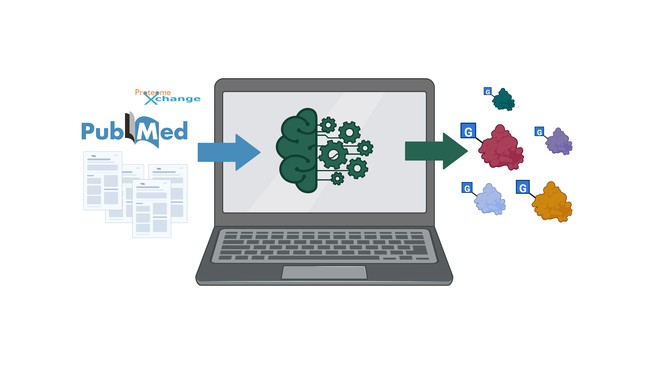
Over zoom, we began a large spreadsheet of all O-GlcNAc-related articles (n=1700). On average, we reviewed 10 articles/day, triaging review articles and focusing on human models. Little by little, we recorded modified proteins and the amino acids localization of the modification (if available) on a massive table until June 2020. Since the disappearance of the other O-GlcNAc database (dbOGA) in 2011, we had just created the only inventory of the human O-GlcNAcome. Helped by a combination of text-mining and machine learning (described in Malard F et al., 2021), we pursued the curation of O-GlcNAc proteins from other 42 species by automatically fetching newly published articles, extracting relevant sentences, protein ID, and species information, performing quality control on identified sites, all this using a user-friendly interface. Overall, our average curation time went from 20 minutes to less than 5 minutes/article. The curation interface is available to all lab members for a participative and continuous database update. This engaging database is also an educational tool, teaching every lab member how to efficiently read articles. Finally, this resource is free to users and us, hosted on MCW servers. The last feature we want to highlight is data impartiality. Indeed, with new identification protocols published monthly, researchers diverge on proper methods to identify O-GlcNAc proteins. Rather than make judgment calls, we came up with a confidence score. Thus, we integrate everything, and proteins are sorted based on the number of articles showing identification, the number of teams that have identified it, and the number of years between identification, emphasizing the enhancement of instrumentations. Altogether, this score gives users some clue as to how well this protein has been characterized.
We relied on existing cataloging tools to structure our database, including UniProtKB ID and canonical sequence, and PUBMED PMID. This permitted cross-referencing the O-GlcNAc database to other websites and increased our reach to other biomedical fields.
We also took advantage of existing databases to compare our performance. The most comparable post-translational modification to O-GlcNAcylation is phosphorylation. However, many kinases accommodate specific consensus sequences, automating the search for phosphorylation sites. In comparison, one enzyme (O-GlcNAc transferase) modifies over 7,800 human proteins, and we created a semi-consensus sequence from 11,691 O-GlcNAc sites. Thus, 80 years after the discovery of protein phosphorylation, O-GlcNAcylation marches in its steps, foreseeing great clinical application for O-GlcNAcylation.
The template we used has been made available to everybody to use. We have made all our front and backend code available to the community (Python package utilsovs, Malard et al., 2021). We hope this software model will be helpful beyond the O-GlcNAc community to quickly set up new smart, online scientific databases. Indeed, this database system can be administrated with little to no programming skills and is meant to be an example of a valuable, sustainable, and cost-efficient resource that exclusively relies on free, open-source software elements (Malard et al., 2021).
O-GlcNAcylation is deregulated in many diseases, including neurodegeneration (Tau, precursor Amyloid, synuclein…), all cancers studied to date, diabetes, and X-linked intellectual disabilities (7 OGT mutations described to date). With the emergence of O-GlcNAc PET ligands, the development of novel O-GlcNAc inhibitors suitable for human trials, and the use of nanobodies for drug delivery, the O-GlcNAc pathway rapidly emerges as a novel diagnostic and therapeutic target. We strongly believe that we have created the most extensive and sustainable O-GlcNAc repository, aiming to assist clinical research by identifying biomarkers and drug targets to better diagnose and treat O-GlcNAc-related diseases.
Since its launch, the O-GlcNAc database has reached more than 5,000 unique users from over 30 countries, with an average weekly traffic of 120 visitors (Google Analytics). With more than 80% returning users and an average engagement time of 2:05min, the O-GlcNAc database is attractive and efficient in looking for O-GlcNAcylated protein information.
Inspired by social platforms, we have also included “Comment” fields in the database to engage the scientific community in identifying mistakes or improvements that can be made.