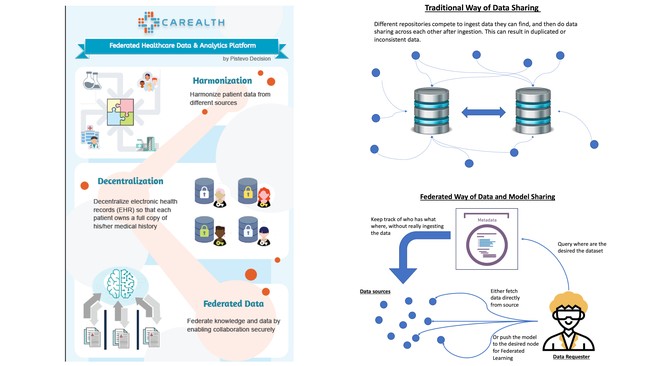
Data is “Fire”. Once it’s shared, you cannot control how the recipient will pass it along. Moreover, copying will make the data out of sync when the source updates. Our approach helps individual patients to collect their updated medical record in the cloud storage of their own choice. Metadata is used to keep track of who has what data where. A sharing request can then check with the metadata to locate the matching data set, if the data owner approves. This network also forms the backbone of Federated Learning to train machine learning models in a decentralized manner without giving out data to further protect owner’s privacy. When combined with differential privacy and homomorphic encryption techniques, models can be protected as well.
Our team composes of 3 key expertise: Data, Artificial Intelligence (AI) and Healthcare
Calvin Chiew is the lead of Medicare Advantage Encounter Data Dashboard and Analytics project, which leverages advanced analytics to unleash Medicare Advantage Part C data. The result is published in the CMS website and received the 2018 FedHealthIT Innovation Award. Chiew and Team Captain Cupid Chan were coworker. Chan is the Chair of BI & AI Committee at Linux Foundation LF AI and Data, where he works with industry leaders to define standards, best practices, and publish white papers. This role exposes him to the latest AI technologies including Federated Learning, which is one of the keys in this proposed solution. Few years ago, Chan met with Dr Ferdinand Hui at a healthcare AI event where they were speakers. Hui then introduced Chan and Chiew to his collogues at Johns Hopkins, Dr Harry Quon, an Oncologist with over 25 years of experience, and Dr Phil Phan, former Business School Senior Executive Vice Dean specializing in entrepreneurship. After sharing the frustration with healthcare system and brainstorming ideas to tackle the problem, they cofounded a company to tackle healthcare data issue using novice approach with latest technology.
Our goal is to allow patients to control their clinical data, and a sharing consent that enables data to be used, and potentially monetized, in a transparent and ethical fashion. This is realized in 3 phases.
Harmonization: Quality data sharing relies on the underneath data integrity. Patient data is used to scatter around various Electronic Health Record (EHR) systems. But because ONC Final Rule enacted in December 2021, patients can now request for their data electronically for free. So, our first step is to motivate patients by collecting their data for them and help them to understand their health holistically. This enables us to harmonize health data from different sources. We applied this concept in a use case of Social Determinant of Health in Oncology and won an NIH SBIR Award last year.
Decentralization: Harmonized data is stored in the patients’ choice of their Cloud storage, including Google Drive, OneDrive, or Dropbox etc. Upon patient’s consent, we facilitate data sharing to the grantee, such as their doctors, by retrieving data directly from patient’s Cloud storage. We will expand it further by enabling researcher to query what type of data they need, e.g., 40 years old black female smoker with blood type B. Since metadata keeps track of who has what data where, this query allows matching data sets returning to the researcher in a decentralized manner.
Federated: Some users may be willing to contribute their data for research but concerned about their privacy. In this case, the Federated Learning layer sitting on top on the decentralized network will help. This allows researchers to push out a model and the training will take place where the data resides. By applying differential privacy technique, no information will be leaked to the requester to protect the data owner’s privacy. The owner can also be incentivized by “name your own price” and get paid for their data being used. On contrary to the traditional approach, Federated Learning prevents revealing of the actual data which causes degrading of its value immediately since the recipient can clone it, out of the data owner’s control.
This architecture protects not only data owner’s privacy when data is shared, but also confidentiality when the model is deployed. By leveraging homomorphic encryption, both data and model can be protected bi-directionally. To close the loop of the cycle, a well-trained model can leverage this same platform to identify matching users for whom can benefit from it.
For replicability, we adopt Fast Healthcare Interoperability Resources (FHIR) standard for data formats and elements and an application programming interface (API) to exchange electronic health records. This is endorsed by the ONC Final Rule which includes a provision requiring that patients can electronically access all their electronic health information, structured and/or unstructured, at no cost. We store this sensitive data by multi-level key which is compliant with financial and healthcare industry standard. Regarding to the integration with other EHR systems, we adopt Substitutable Medical Applications and Reusable Technologies (SMART) on FHIR, which leverages the OAuth 2.0 standard to provide secure, universal access to EHRs.
On the frontend, we use NativeScript to build Mobile App interacting with users with the same code base for both iOS and Android. For users preferred browser, we leverage Angular to build a modernized web application. Both Web and Mobile Apps connect to our serverless backend written in TypeScript and Node.js to provide a scalable platform as demand expands. PyTorch and TensorFlow are selected as our AI framework to provide machine learning and Federated Learning support.
Since all standards and technologies used in this platform is open-sourced, replicated by other teams is easy and “free”. To reduce the friction even further, our company plans to open source our own code in the future once it is proven stable with user adoption.
“Share data = Sacrifice success” is one of the common reasons and misconceptions of why people are not willing to share data.
It’s a common reason because data is the foundation of most research. People usually take quite a lot of time and effort to collect good quality data. Sharing data means someone else get it for free and can achieve the goal sooner with less effort.
It’s a misconception because sharing data can make the sharer and even the whole community more successful. This is true not only for data. Everyone’s success is built on top of works done previously by others, who are also willing to share their result selflessly. This phenomenon is particularly true for the technology industry in the recent years when “open-source” becomes the formula to expand a project and encourage collaboration internationally. This result makes these sharers more successful than proprietary software. One of a recent success examples is Databricks, which grounds on an open-source project Apache Spark and raised over $3.5B in less than 10 years.
While data privacy could be a valid concern, we can apply appropriate technologies like what we described in this submission to achieve “Share data = Share success”
