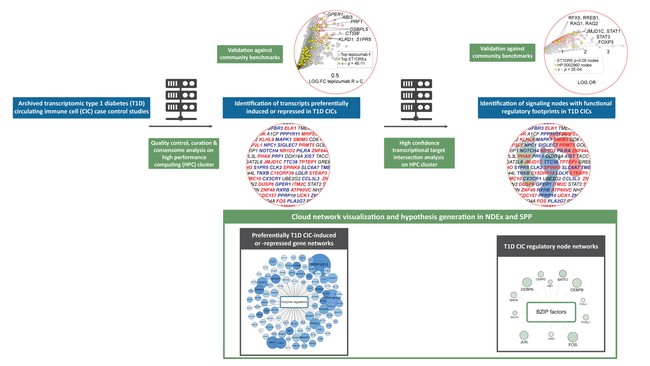
Here we repurposed Investigator-generated transcriptomic datasets interrogating circulating immune cell (CIC) gene expression in clinical type 1 diabetes (T1D). We firstly computed sets of genes that were preferentially induced or repressed in T1D CICs and validated these against community benchmarks. We then inferred and validated signaling node networks regulating expression of these gene sets. In three use cases, we demonstrated how informed integration of these networks with complementary digital resources supports substantive hypotheses around T1D pathways in CICs. Finally, we developed a federated, cloud-based web resource that exposes the entire data matrix for unrestricted access and re-use by the research community.
Dr Neil McKenna leads the team. Trained as a cell biologist, he has 20 years experience in data sharing and re-use initiatives. Reflecting this experience, he led the first data repository in the US to mint digital object identifiers as unique identifiers for datasets. He currently leads the Signaling Pathways Project (SPP), a trans-omics knowledgebase for cellular signaling pathways. His career goal is to give datasets parity of esteem with research articles.
Dr Jeff Grethe is PI of the NIDDK Information Network (DKNET) and a long time collaborator of Dr McKenna in various NIH and FAIR data initiatives such as BD2K and DataMed. His group maintains the cloud environment in which the T1D regulatory networks are hosted, as well as SPP.
Dr Scott Ochsner joined Dr McKenna's group in 2009 after graduate research in molecular reproductive biology. He's never met a dataset he didn't want to put through R and is happy to do the leg work required to throw a lens on to an RNA-Seq dataset to make sense of its biology.
Last but not least, Dr Rudi Pillich is a senior curator at NDEx, developed by the same group that brought you Cytoscape. Rudi makes all our letters and numbers look visually engaging and informative in the NDEx website
Period of time and goals
In the summer of 2021, we embarked on an effort to identify and curate datasets profiling gene expression in type 1 diabetes (T1D) circulating immune cells. Firstly, we surveyed across these datasets to identify genes that exhibited significant tendencies towards preferential induction or repression in T1D CICs. Secondly, we computed these datasets against millions of existing archived transcriptomic and ChIP-Seq data points relevant to cellular signaling nodes to enable the prediction of T1D transcriptional regulatory networks. Thirdly, we developed a federated web-based visualization environment to promote engagement of these networks by the broader research community.
What data sharing and/or reuse practices has your team adopted?
We believe that the value of any new 'omics dataset is increased exponentially if it is placed in the context of the thousands of 'omics datasets that already exist. We have developed a data re-use pipeline whose goal is to connect signaling pathway nodes, disease states and gene expression in a single informatic environment. Our data re-use and annotation experience stretches back to the early 2000s, when Dr McKenna led the Nuclear Receptor Signaling Atlas, an early big data community initiative to share datasets via the web from a consortium of nuclear receptor scientists.
What data sharing or reuse practices would you recommend all researchers adopt, and why?
Annotate, annotate, annotate. Data are nothing without context. By all means ensure that your datasets are technically robust, but also provide as much information you can as around the biology of the dataset - genes or proteins involved, cell type, small molecule treatments. All this information is tremendously valuable to curators.
What do you think is compelling about how you shared or reused data?
A critical component of our study is the availability of the T1D circulating immune cell predictive networks in a freely-accessible, federated web resource. The broad, cross-domain userbases of NDEx and SPP will give investigators across diverse fields the opportunity to bring their own domain- and paradigm-specific expertise to bear upon the complexity of T1D. Making the data matrix available in two resources that place a high priority on ease of use enables bench researchers to benefit from the results of analytical approaches that are more typically the preserve of laboratories with advanced informatics expertise and computational infrastructure.
The Signaling Pathways Project (SPP) seeks to enhance the FAIR (findability, accessibility, interoperability and re-use) status of public cell signaling ‘omics datasets along three dimensions. Firstly, SPP encompasses datasets involving genetic and small molecule perturbations of a broad range of cellular signaling pathway modules - receptors, enzymes, transcription factors and their co-nodes. Secondly, SPP integrates transcriptomic datasets with biocurated ChIP-Seq datasets, documenting genomic occupancy by transcription factors, enzymes and other factors. Thirdly, we have developed a meta-analysis technique that surveys across transcriptomic datasets to generate consensus ranked signatures, referred to as consensomes, which allow for prediction of signaling pathway node-target and disease regulatory relationships. To ensure that our efforts are broadly aligned with established community standards, we have adapted existing, mature classifications for receptors (International Union of Pharmacology, IUPHAR), enzymes (International Union of Biochemistry and Molecular Biology Enzyme Committee) and transcription factors (TFClass). On the technical level we make extensive use of open web technologies and application programming interfaces to ensure maximum interoperability with other resources. All our standard operating procedures have been extensively documented in the publications listed to facilitate replication by other resources.
The motivation for developing this resource was to help make sophisticated analyses of the transcriptional basis of type 1 diabetes in circulating immune cells more accessible to the scientific community. When researchers have open access to each other’s work, discoveries move forward more efficiently. We believe that informatics should not be the exclusive preserve of informaticians - the great leaps made in web development over the last 20 years have made it much easier to present multi-dimensional data in intutive and accessible user interfaces. A picture really does tell a thousand words, and the level of visual accessibility that NDEx affords our analyses
There's a saying that goes "All of Us Are Smarter Than Any One of Us" that we feel is particularly apt to omics data sharing. By leveraging the billions of data points that have already been generated by the research community, we can profoundly increase the impact of any one dataset. This is the principle of the Signaling Pathways Project.
