The rapid growth in complexity of both data types and computational methods has led to widespread inconsistencies in how biomedical data is processed. This lack of reproducible data processing pipelines has created a gulf between the raw data and the processed data used for modelling that facilitates the development of predictive clinical tools. The Phi-HARMONY team is working to fill this critical knowledge gap by (a) providing higher-quality, consistent data with (b) transparent and harmonized metadata that are analysis-ready, along with (c) exemplar analysis pipelines that leverage these datasets. Significant headway has been made towards these goals via our open-source ORCESTRA platform (orcestra.ca; Nature Comm 2021).
Our global team has diversity in representation and expertise. Dr. Caroline Chung is Chief Data Officer at MD Anderson Cancer Center (USA, Canada trained) with experience in building an ecosystem for data science and scientific expertise in multimodal data analysis and quantitative imaging. Dr. Benjamin Haibe-Kains is an ML expert applied to genomics and radiological data for cancer. As the Canada Research Chair in Computational Pharmacogenomics (Canada, Belgium trained), he has championed open science and research reproducibility. Dr. Tero Aittokallio, a leader at the Institute for Molecular Medicine Finland (FIMM) and Oslo University Hospital (Norway), has made seminal contributions in the field of pharmacogenomics and biomarker discovery. Dr. Marc Hafner is a Senior Scientist in Computational Biology and Discovery Oncology at Roche/Genentech (USA, Switzerland trained) developing new statistical and ML methods to analyze large-scale phenogenomics data. The ORCESTRA Team (Canada; Nikta Feizi, Sisira Nair, Chris Eeles, Minoru Nakano, and Parinaz Nasr Esfahani) integrates clinical trial data and develops clinical trials objects, produces code-based tutorials for each dataset, and supports infrastructure and interface improvements.
The first public release of ORCESTRA in October 2021 [1] allowed the whole scientific community to access an initial set of highly-curated, harmonized, analysis-ready datasets for their own research to accelerate the creation of new preclinical and clinical hypotheses and/or validate prior findings leveraging these data. Since the original publication in Nature Communications, we have added 3 pharmacogenomics datasets (NCI60, PRISM, Glioblastoma) and 14 clinical genomics datasets (https://www.orcestra.ca/clinicalgenomics). This is a ~94% increase in the number of integrated datasets within 3 months. Despite being only recently published, the platform has already attracted 1440 users from 62 countries since the start of 2021, with the majority accessing the platform from Canada (n=468), the United States (n=465), Europe (n=227) and China (n=135).
In addition to increasing the portfolio of available datasets, the Phi-HARMONY team is actively working to align ORCESTRA with other initiatives supporting the harmonization of multimodal data. We are closely working with Dr. Hafner at Genentech to integrate the harmonized pharmacogenomic datasets into their gDR platform for better standardization of drug response data and their storage in a central database that can cover multiple labs and screening facilities. Recognizing that the principles underlying ORCESTRA are not limited to the field of genomics, we are actively expanding the ORCESTRA functionalities to include new data types such as medical imaging and their metadata generated in clinical settings. This will be crucial to make the processing of clinical data and their modeling more transparent and reproducible, a key step towards the successful deployment of diagnostic, prognostic, and predictive tools in the clinic.
Based on users’ feedback, we are maturing the data governance model to include private datasets in ORCESTRA that can be shared with other internal users, prior to public release. This will allow data generators to start the harmonization process early in the data life cycle and run quality control, unit testing, and documentation before global release.
Altogether, ORCESTRA creates an environment that enables reproducible and transparent exposure of data, code and models, allowing researchers to find and build from each other’s projects and data. Ultimately, ORCESTRA will improve the way scientists use each other’s work with appropriate attribution and thereby, accelerate new discoveries.
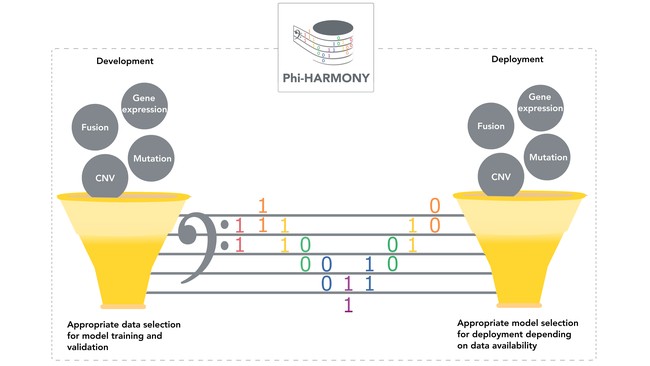
Phi-HARMONY leverages existing standards to improve replicability across the data science pipeline from data aggregation to clinical deployment of computational models:
The Phi-HARMONY team leverages the open-source and replicable nature of ORCESTRA to provide analysis-ready data along with the computational resources needed to maximize outreach and engagement across a diverse community of researchers and developers who can solely focus on utilizing their expertise purely towards computational analysis and interpretation of results. ORCESTRA increases the FAIRness of biomedical datasets by allowing researchers, whose limited resources prevent them from downloading and curating large raw biomedical data, to focus on data analysis and implementation of innovative methods.
Beyond aggregating and harmonizing the data, ORCESTRA provides transparency in the metadata, which can help unveil sources and impacts of bias within the data themselves or along the data processing steps. This transparency can additionally facilitate a broader range of research questions raised by academic, industry and technology collaborators across disparate domains and topics to inform and improve global health.
Fundamentally, the Phi-HARMONY team aims to drive a culture change in cancer research, placing greater importance on the need for transparent, reproducible data processing.